
Read replicas in Neon are different from what you’re used to – they’re lightweight, affordable, and fast to provision. You can rely on them to scale your performance horizontally when you need a boost. We’ve been working hard on our read replicas lately, improving their stability via numerous fixes. Explore our code in Github (Neon is open source).
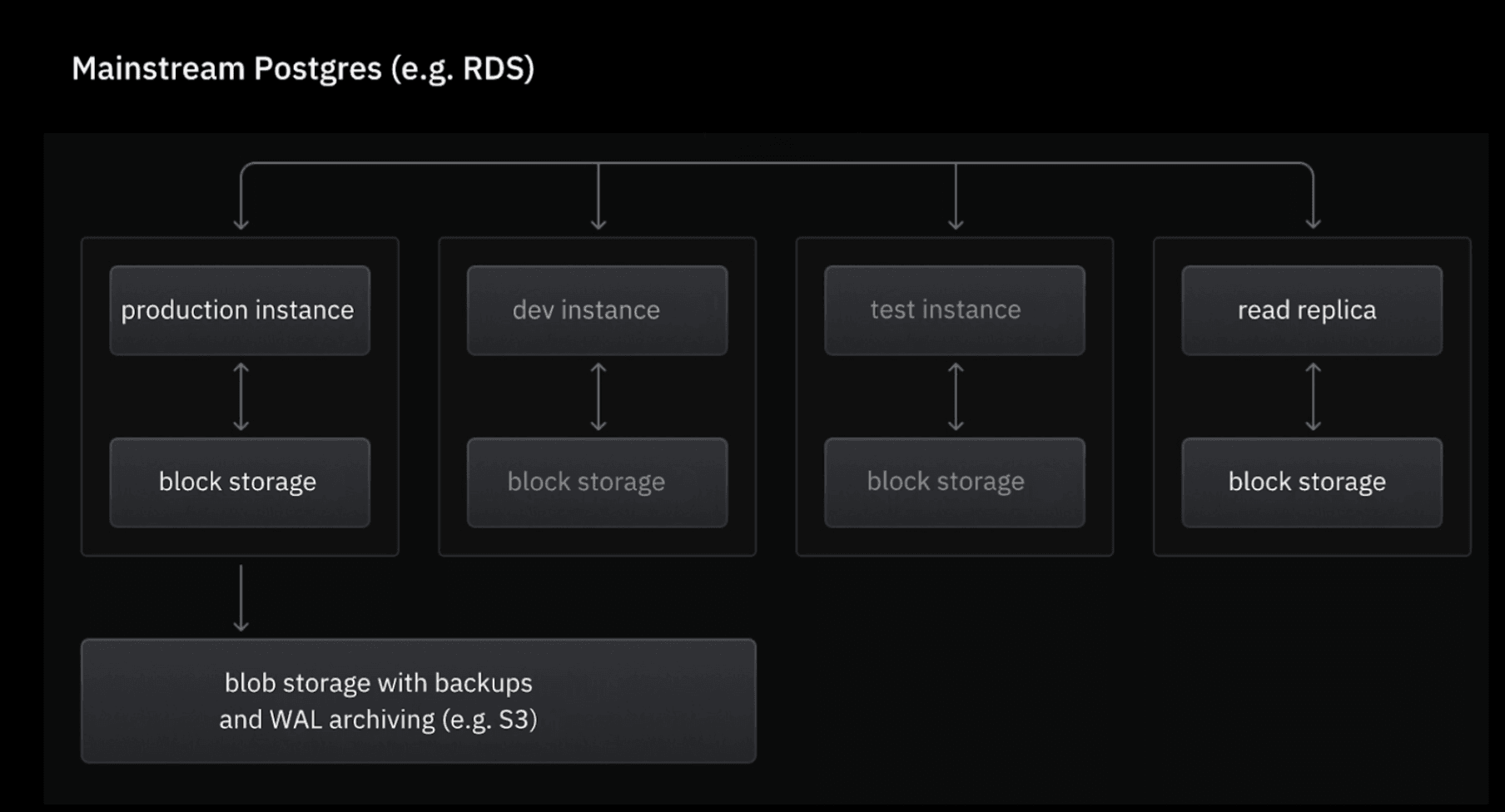
In most managed Postgres databases (where compute and storage are coupled) replicas are a perfect duplicate of the instance, including compute and storage. The hypothesis with replicas is that by being able to replicate the production database, users will be able to solve two different problems:
- High availability (HA). When used in this context, replicas are often referred to as standby nodes. They introduce a failover mechanism to ensure that the database remains available even if the primary node fails. The common mechanism is having the primary node continuously stream its WAL to the replica, which applies the changes to stay in sync.
- Performance scaling. Now, you would call these read replicas. They are being used to offload read-intensive queries from the primary node – balancing the load and improving overall performance. Applications can be configured to send read-only queries to replicas, reducing the burden on the primary node and allowing it to focus on write operations.
If you’re using a managed database and you’re interested in the high availability problem, replicating the full instance may make sense.
But what you’re interested in scaling performance efficiently? On paper, replicas seem like a great cloud-native solution for this. If your app experiences important spikes in load during certain events, in theory, you could rely on quickly spinning up read replicas, route the heavier read queries to these read replicas, and save the primary instance for all the writes. This would effectively balance your load, avoiding bottlenecks, without implementing complicated Postgres shardings or other strategies on the DB layer.
This is good in theory, but the reality is this: due to fundamental issues in the architecture of most managed Postgres solutions, replicas become a very inefficient way to scale performance.
Why is the read replicas experience so bad?
Read replicas are an inefficient way to scale due to a few fundamental reasons, all ingrained in the architecture of most managed Postgres:
- Data redundancy in read replicas is a feature, not a bug.
Read replicas are traditionally implemented as separate instances duplicating the production database, including storage. If the purpose of the replica was to improve availability in the database, it’s perhaps a good thing to include data redundancy in the implementation – but if we want to use replicas for scaling, this is beside the point. What we’re looking for is an efficient, cloud-native way to scale performance for our Postgres database. If for each replica we add, we’re duplicating our entire dataset (and being billed for it), is this really that efficient?
- Read replicas take time to be ready.
Another problem that comes with this (unwanted) duplication of storage is all the overheads associated with more database instances. If spinning up a read replica involves provisioning a new instance with a full copy of the dataset, at the very least it will take minutes for the read replica to be operational. This can easily move closer to the hour range when your database is large. And if you can’t rely on spinning replicas up quickly when you need them, you have to create them in advance. At the very least, this means you’ll be paying for duplicated storage 24/7. And you will also be paying for unused compute unless you manually pause and resume them…
- Read replicas are always on, even when not needed.
…and not many teams do this. Resuming paused replicas is usually a manual process, and this cold start takes a while. Most teams will keep their read replicas running most of the time. They’ll be paying for redundant storage 24/ and also for extra compute 24/7, even when it’s not needed.
How a serverless architecture improves this
“We’re using read replicas in Neon (in conjunction with our use of Hasura) because they were so easy to setup. This allows us to offload read-only API calls in our application, currently the majority of API calls we receive, from our primary/write instance to keep responses snappy.“
Hybound
All combined, this experience sucks. The result is not what was originally promised—an agile way to horizontally scale database performance by leveraging cloud infra—but an expensive architecture full of redundancies that’s too slow to meet the needs of modern apps.
Neon’s architecture is very different from the traditional managed database. It has a natively decoupled architecture with separated compute and storage, and it also incorporates an innovative storage engine that records database history and combines SSDs for performance with S3 for durability.
This allows Neon to reimagine Postgres replicas:
- Since Neon’s storage is already highly durable and separate from compute, the primary need for replicas for HA is diminished. The storage layer is designed to be resilient and can survive failures without relying on replicas.
- Read replicas can be implemented differently to focus solely on scaling read operations without the redundancy associated with traditional replicas. Compute nodes can be provisioned as needed to handle read queries, leveraging the shared durable storage.
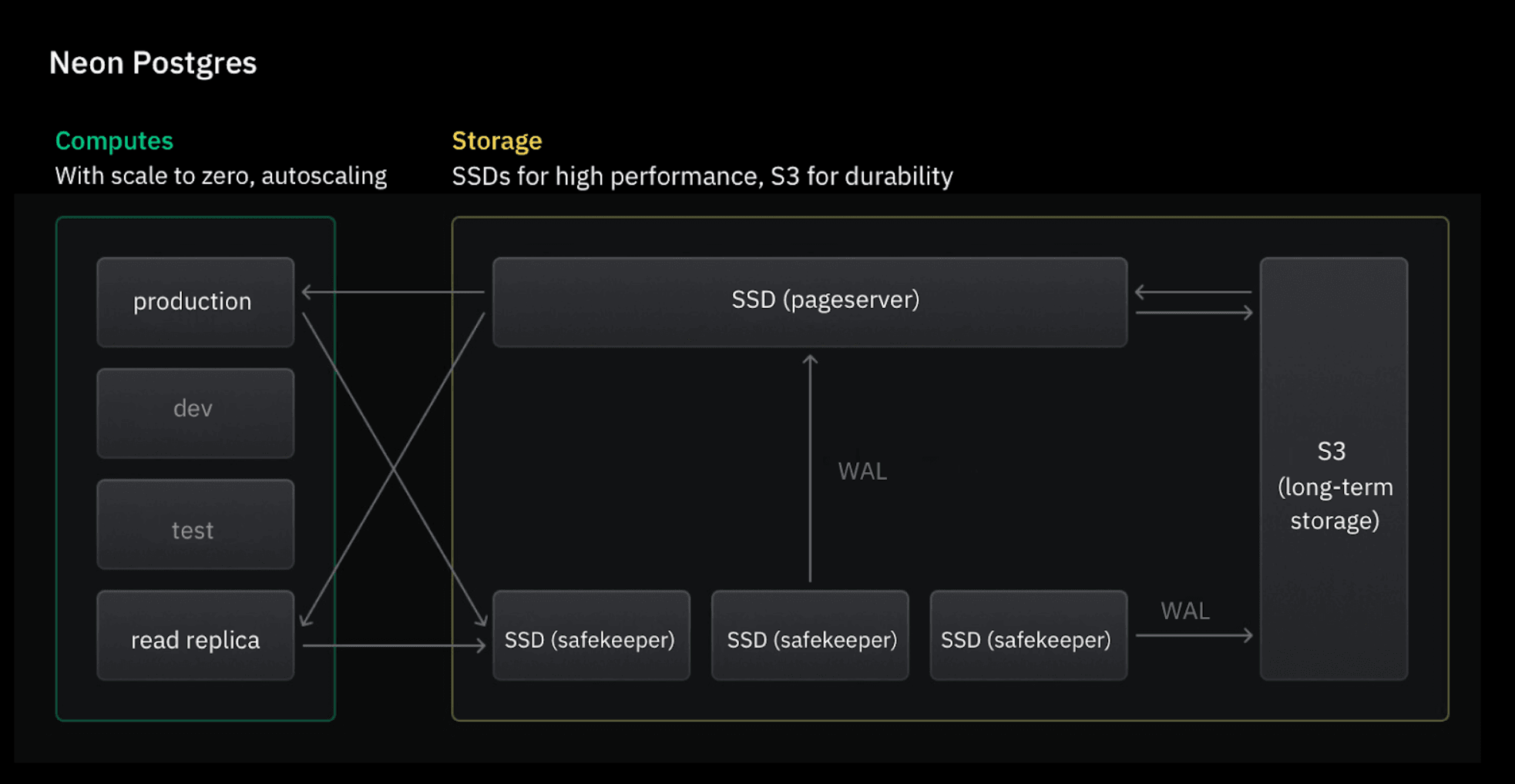
Read replicas in Neon don’t duplicate storage
Neon’s read replicas are ephemeral, meaning they are just additional compute instances attached to your existing storage. Unlike traditional read replicas that require duplicating your entire database, Neon’s replicas dynamically use the same storage, eliminating the need for storage copies. This design allows for instant provisioning, with replicas ready to use in just a few milliseconds, avoiding lengthy setup times.
| Read replicas in Neon | Read replicas in RDS | |
|---|---|---|
| Implementation | Compute-only, attached to existing storage | Full instance duplicates |
| Provisioning time | Instant | Takes many minutes |
| Additional storage costs | None | Doubled due to redundancy |
| Compute costs | Scale to zero, pay only for compute when in use | Always on, manual pausing required |
| Restarting time | < 500 ms, after scale to zero | Several minutes, after manual restart |
| Redundancy | None | Inherent |
| Performance | Autoscales according to fluctuating read demands | Less flexible, tied to instance resizes |
| Management | Minimal manual intervention needed | Requires manual configuration |
Read replicas in Neon scale to zero and autoscale
“Our main compute dynamically adjusts between the minimum and maximum CPU/memory limits we’ve set. This gives us performance and cost-efficiency. By routing our read queries to read replicas during high traffic periods, we ease the load on our main compute”
White Widget
Neon’s read replicas are even more cost-effective because they scale to zero – you only pay for compute when queries are active. When there’s no read traffic, replicas automatically pause and restart in milliseconds when needed.
This gets combined with autoscaling to scale up Postgres performance scaling without overpaying. For example, during a traffic spike on a SaaS platform, Neon can wake up read replicas instantly to manage the increased read load, letting the primary database focus on write operations. Autoscaling adjusts compute resources for both the primary and read replicas according to demand, scaling up during peak traffic and back down, eventually to zero, when load dies.
How to try it
You can create and configure read replicas to any database branch in Neon using the console, the CLI, or the API. When specifying the compute capacity of the read replica, you can select the autoscaling range (e.g. from 0.125-1 CU) and also configure scale to zero.
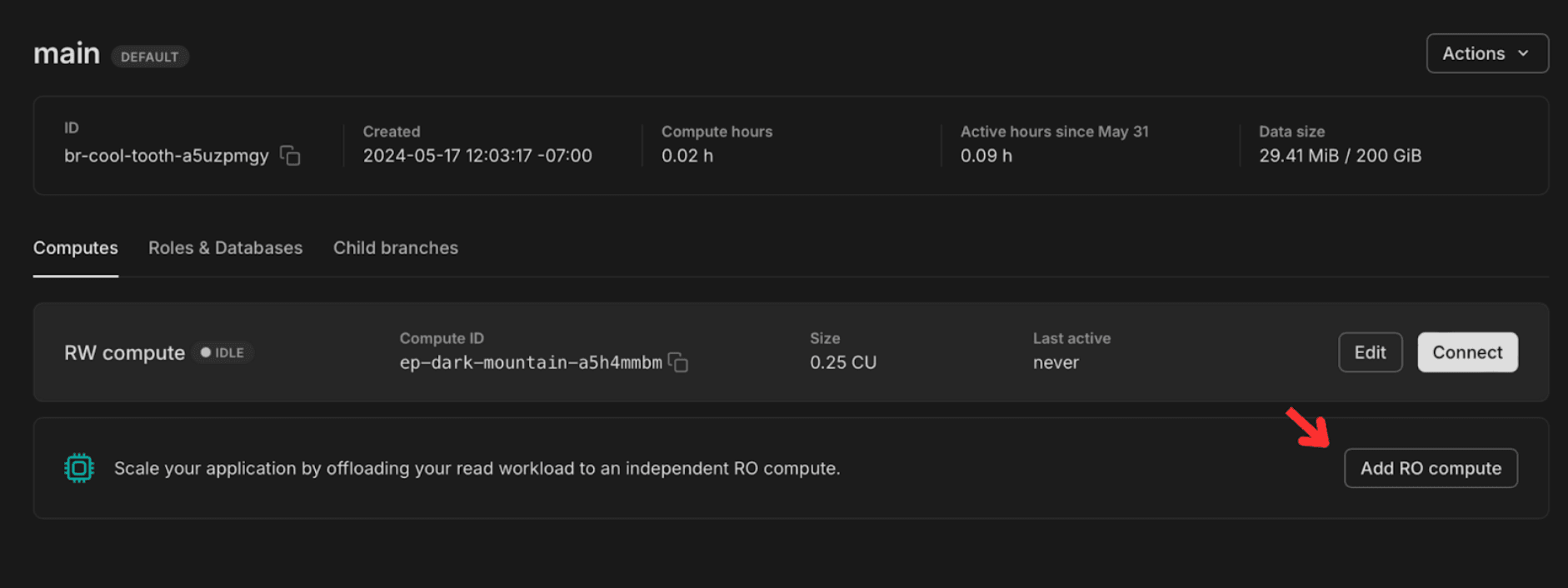
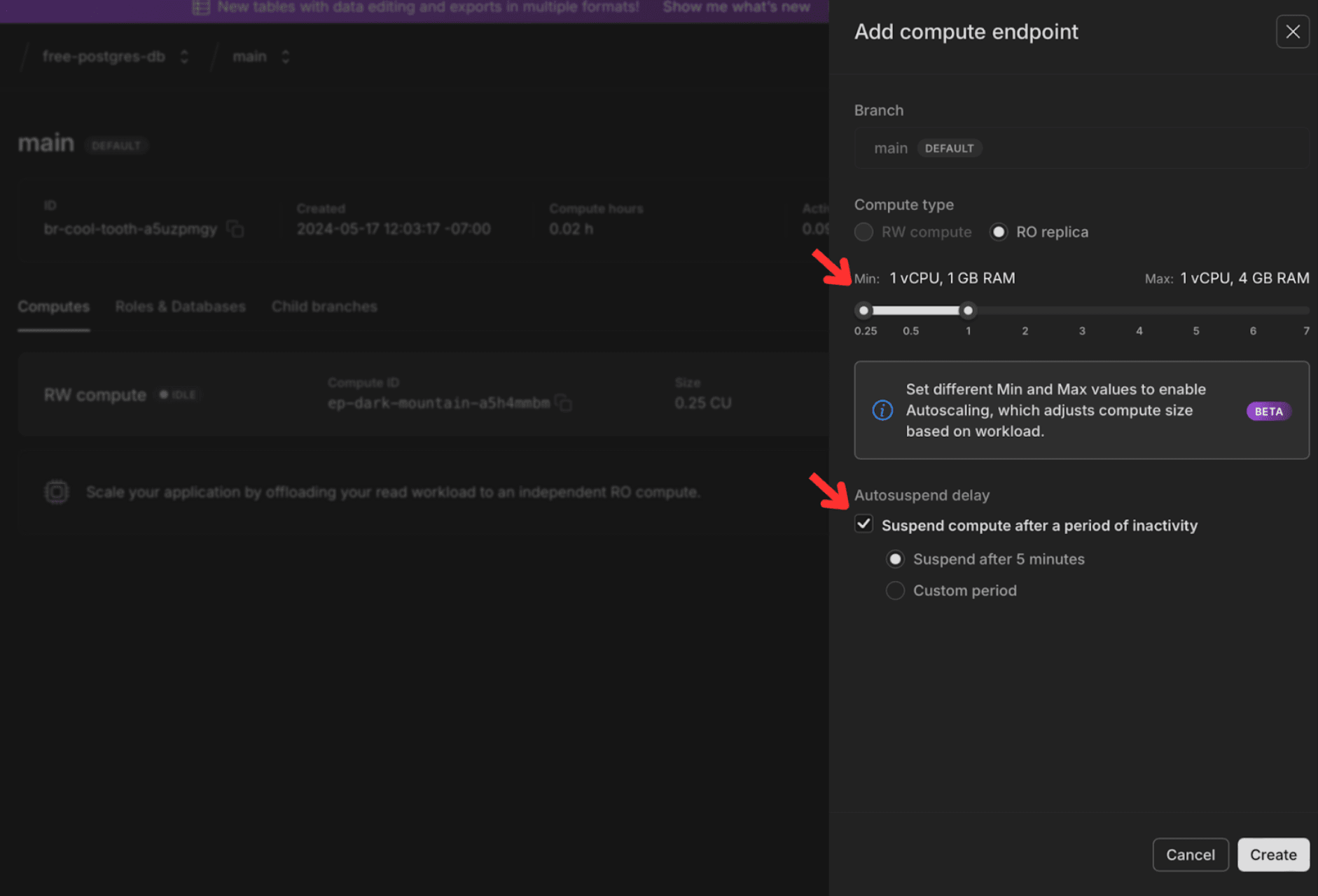
Connecting to a branch via a read replica is equivalent to doing it via the main compute. You can view the dedicated URL via the console or by running get endpoints in the API. Check our docs for all the info on how to work with read replicas.
A better way to scale Postgres performance
It’s possible to scale Postgres performance horizontally without overpaying. Read replicas are a good idea, they’re just hard to implement well without a serverless architecture – and that’s where Neon has an advantage.
We’re working hard to build read replicas in Neon in a way that are truly usable for performance scaling, as an alternative to provisioning very large CPU/memory in primary instances or implementing very complex table shardings. If you want to try them out, replicas are included in the Neon Launch plan ($19 / month) but you can also try them for free by requesting a free trial.



